publications
2025
- T1T2Benchmark
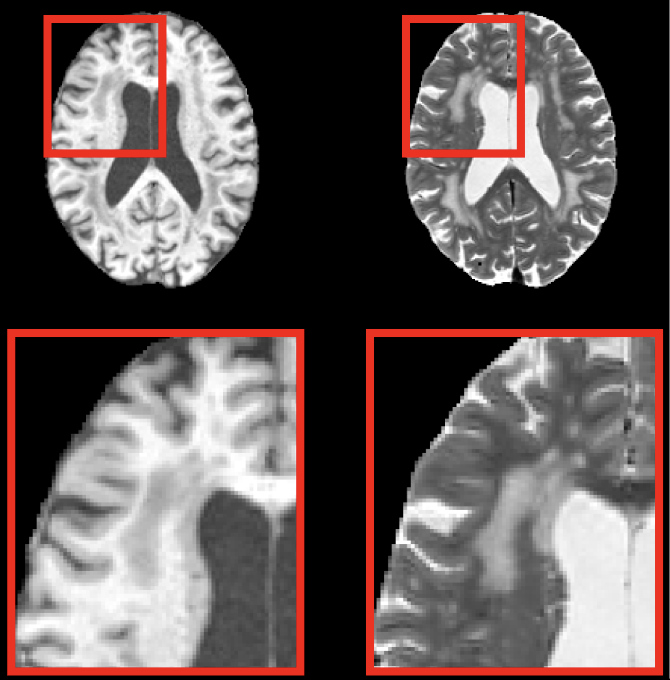 Benchmarking GANs, Diffusion Models, and Flow Matching for T1w-to-T2w MRI TranslationAndrea Moschetto, Lemuel Puglisi, Alec Sargood, and 4 more authors2025
Benchmarking GANs, Diffusion Models, and Flow Matching for T1w-to-T2w MRI TranslationAndrea Moschetto, Lemuel Puglisi, Alec Sargood, and 4 more authors2025Magnetic Resonance Imaging (MRI) enables the acquisition of multiple image contrasts, such as T1-weighted (T1w) and T2-weighted (T2w) scans, each offering distinct diagnostic insights. However, acquiring all desired modalities increases scan time and cost, motivating research into computational methods for cross-modal synthesis. To address this, recent approaches aim to synthesize missing MRI contrasts from those already acquired, reducing acquisition time while preserving diagnostic quality. Image-to-image (I2I) translation provides a promising framework for this task. In this paper, we present a comprehensive benchmark of generative models–specifically, Generative Adversarial Networks (GANs), diffusion models, and flow matching (FM) techniques–for T1w-to-T2w 2D MRI I2I translation. All frameworks are implemented with comparable settings and evaluated on three publicly available MRI datasets of healthy adults. Our quantitative and qualitative analyses show that the GAN-based Pix2Pix model outperforms diffusion and FM-based methods in terms of structural fidelity, image quality, and computational efficiency. Consistent with existing literature, these results suggest that flow-based models are prone to overfitting on small datasets and simpler tasks, and may require more data to match or surpass GAN performance. These findings offer practical guidance for deploying I2I translation techniques in real-world MRI workflows and highlight promising directions for future research in cross-modal medical image synthesis. Code and models are publicly available at https://github.com/AndreaMoschetto/medical-I2I-benchmark.
@misc{moschetto2025benchmarkinggansdiffusionmodels, title = {Benchmarking GANs, Diffusion Models, and Flow Matching for T1w-to-T2w MRI Translation}, author = {Moschetto, Andrea and Puglisi, Lemuel and Sargood, Alec and Dell'Acqua, Pierluigi and Guarnera, Francesco and Battiato, Sebastiano and Ravì, Daniele}, year = {2025}, eprint = {2507.14575}, archiveprefix = {arXiv}, doi = {https://doi.org/10.48550/arXiv.2507.14575}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2507.14575}, }
2024
- FakeSamples
 The Great Textual Hoax: Boosting Sampled String Matching with Fake SamplesSimone Faro, Francesco Pio Marino, Andrea Moschetto, and 2 more authorsIn 12th International Conference on Fun with Algorithms (FUN 2024), May 2024
The Great Textual Hoax: Boosting Sampled String Matching with Fake SamplesSimone Faro, Francesco Pio Marino, Andrea Moschetto, and 2 more authorsIn 12th International Conference on Fun with Algorithms (FUN 2024), May 2024Sampled String Matching is presented as an efficient solution to the string matching problem, aiming to tackle the space constraints of indexed string matching while purportedly reducing search times for online solutions. Despite the problem’s inception dating back to 1991, practical solutions have only recently emerged. These purportedly accelerate online searches by up to 35 times compared to conventional methods, achieved through a partial index occupying a mere 5% of the text size. This paper delves into the intricacies of one of the latest and most effective text sampling techniques, character distance sampling, which revolves around sampling distances between characters of a selected alphabet within the text. Specifically, we introduce fake samples while remaining honest! In other words, the study reveals that, interestingly, strategically introducing fake samples within the sampled sequence slashes the required index space by almost half, just avoid compromising the algorithm’s correctness. Additionally, since efficiency is everything, this approach, in turn, purportedly enhances the algorithm’s efficiency under specific conditions.
@inproceedings{faro_et_al:LIPIcs.FUN.2024.13, author = {Faro, Simone and Marino, Francesco Pio and Moschetto, Andrea and Pavone, Arianna and Scardace, Antonio}, title = {The Great Textual Hoax: Boosting Sampled String Matching with Fake Samples}, booktitle = {12th International Conference on Fun with Algorithms (FUN 2024)}, pages = {13:1--13:17}, isbn = {978-3-95977-314-0}, issn = {1868-8969}, year = {2024}, month = may, volume = {291}, editor = {Broder, Andrei Z. and Tamir, Tami}, publisher = {Schloss Dagstuhl -- Leibniz-Zentrum f{\"u}r Informatik}, address = {Dagstuhl, Germany}, url = {https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs.FUN.2024.13}, urn = {urn:nbn:de:0030-drops-199211}, doi = {10.4230/LIPIcs.FUN.2024.13}, annote = {Keywords: string matching, sampling}, }